Project Proposal
Summary
We will be implementing different parallel implementations of Conway’s Game of Life in 3D. We will be using the NVIDIA GPUs on the GHC machines for our CUDA implementation and the PSC machines for the OpenMP implementation.
Background
Conway’s Game of Life is a Turing complete zero-player cellular automaton, traditionally in 2D, that simulates basic evolution. After giving an initial configuration of alive or dead cells, the pattern evolves based on a set number of rules governed by the neighbors of each cell:
- A cell with
- A cell with
- An empty cell with exactly 3 living neighbors becomes alive (reproduction)
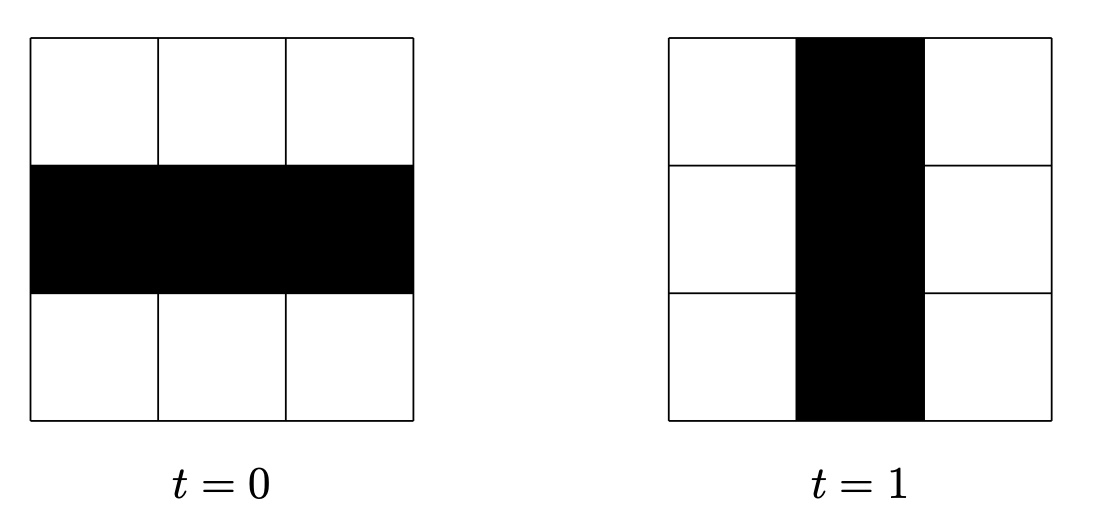 Despite this basic ruleset, there have been many different types of patterns found through studies: still lifes, which do not move; oscillators, which have a periodic form of motion; and spaceships, which drift in a consistent manner across space. Some initial patterns can also lead to infinite growth, where the bounding box of the pattern grows at each timestep. One example of a basic oscillator is shown to the right.
Despite this basic ruleset, there have been many different types of patterns found through studies: still lifes, which do not move; oscillators, which have a periodic form of motion; and spaceships, which drift in a consistent manner across space. Some initial patterns can also lead to infinite growth, where the bounding box of the pattern grows at each timestep. One example of a basic oscillator is shown to the right.
Conway's Game of Life is fairly simple in 2D, as there are only 8 neighbors and 2 axes (x- and y-axis). However, adapting to 3D -- increasing the number of neighbors from 8 to 26 and multiplying the size of the grid by another factor -- greatly increases communication intensity. Furthermore, the z-axis can now be an added area of parallelism.
Another area for potential speedup is the idea converging or stable structures that form in Conway's Game of Life. In the 2D model, all starting states gradually converged to stable structures. Similarly, in 3D, all starting states will also generally remain stable after a certain time, meaning that there will be no need to pass information about empty spaces around unless they are immediate neighbors.
The Challenge
As stated previously, scaling to 3D increases the areas of parallelism and the achievable theoretical speedup. By increasing the number of dimensions, we increase the number of neighbors (8 to 26), meaning we must do more than 3 times as much communication. Furthermore, the number of cells increase from N2 to N3, potentially creating a memory constraint if N becomes large enough.
The main workload of this project revolves around managing locality. Since all computation relies on the state of the neighbors of a cell at any given time, our project has a very high communication-to-computation ratio.
There are also constraints to the workload. There are many possible patterns that the cellular structures can stably converge to, as the cells tend to group around their immediate neighbors. This situation immediately gives rise to the possibility of workload imbalance, as areas with alive cells will need to communicate more than areas with only dead cells (note how all the rules for 2D Conway's Game of Life are based on the number of alive neighbors).
Resources
Some basic aspects of our projects 2 (CUDA) and 3 (OpenMP) are naturally similar due to their methods of parallelism, so we will use them as reference. Our past assignments using CUDA kernels and OpenMP pragmas for 2D programs will help us extend our knowledge to a 3D program.
We have also found a couple of online resources that will be useful. The first website here describes some interesting extensions of the original ruleset for the 3D version. Another website here provides a useful guide to rendering in OpenGL, which we would like to build upon to render our results.
Goals and Deliverables
Plan to Achieve
We expect to achieve the following tasks within the time frame. Note that all three implementations should output their results in a common text format so that we can judge correctness and easily render results.
- Sequential Implementation - a naive, sequential implementation of the 3D Game of Life that can be used as a comparison to our parallel implementations.
- Parallel CUDA Implementation - a parallel implementation of the 3D Game of Life in CUDA that achieves significant speedup in comparison to our sequential version. It should work to minimize computation and workload imbalance.
- Parallel OpenMP Implementation - a parallel implementation of the 3D Game of Life in OpenMP that achieves significant speedup in comparison to our sequential version. Similarly, it should work to minimize computation and workload imbalance.
- Visualizations for Debugging Purposes in OpenGL - a basic, non-interactive renderer of our output data that visualizes the cube and each simulation step. This is an important step to ensure correctness of our implementations and it allows for visual debugging.
Hope to Achieve
While not strictly necessary for this project, we would like to achieve some of the following as well.
- Parallel MPI Implementation - If we have a siginificant amount of extra time, we would like to create a third parallel implementation based on MPI. It would add to our speedup analysis of our main two parallel implementations.
- Interactive Visualizations in OpenGL - This would expand upon the basic debugging renderer and allow for more interactivity. You would be able to rotate the cube while it simulates and it would be more visually polished. This would be a great way to show off our results.
- Experimentation with Various Rulesets - We would like to try implementing variations on the traditional game ruleset. Not only would this be visually interesting, but it would also allow further analysis of how our code performs more generally. Changing the ruleset can impact the density of living cells, the way in which they group together, and how the simulation changes over time. All of these factors have the potential to impact the performance of our implementations due to changes in workload imbalance and communication costs.
- Integrating OpenGL rendering with our CUDA implementation - CUDA and OpenGL can work well together as they both make significant use of the GPU. OpenGL has the capability to directly access CUDA GPU memory and significantly speed up the rendering process. Our planned implementation does not take advantage of this compatibility. We would like to see how integrating the CUDA simulation and OpenGL rendering code affects performance if we have time.
Demo
In terms of speedup analysis, we will have graphs that show how our sequential and parallel implementations perform in a variety of scenarios. Varying cube size and starting configurations can all impact performance in different ways. By measuring how each implementation handles these changes, we can provide a more complete picture of our final results. We will also have a small discussion about the relative strengths and weaknesses of both parallel implementations.
Visually, we will have at a minimum our simple debugging renderer in OpenGL to showcase some of the simulations. Hopefully, we will have time to polish this a little more for the final demo.
Analysis
This project will help us better our understanding of the relative strengths and weaknesses of OpenMP and CUDA as we analyze our results. Specifically, we will see how these implementations perform large tasks that involve a high communication-to-communication ratio and workload imbalance.
Performance Goals
While concrete speedups for our two implementations are difficult to estimate, we hope to achieve at least a 10x speedup for both the CUDA and OpenMP implementations. In theory each cell could be perfectly parallelized and lead to much more than a 10x improvement, but we predict that high communication costs and workload imbalance will limit our implementations. Thus, 10x speedup is a reasonable goal that shows significant improvement over the sequential implementation while still accounting for limiting factors.
Platform Choice
For the sequential implementation, we will code in C++ and measure it on the PSC machines (CPU). For the CUDA implementation, we will code in CUDA and measure it on the PSC machines (GPU). Finally, for the OpenMP implementation, we will code in OpenMP and measure it on the PSC machines (CPU). The renderer will be made using OpenGL.
Schedule
| Date | Goal |
|---|---|
| March 31 | Project proposal done |
| April 1-8 | Basic visualizations done |
| April 9-10 | Basic sequential version complete |
| April 11-21 | Cuda and OpenMP versions done |
| April 18 | Project Milestone Report |
| April 22 - May 4 | Work on any stretch goals |
| May 4-5 | Final report and presentation complete |